Deux ou trois fois par an, Start it @KBC Startit fait un appel à des candidatures pour que les nouvelles startups puissent intégrer son programme accélérateur de startup. Ce programme permet aux startups de trouver un lieu pour croître mieux et plus rapidement. A priori, les startups rejoignent l’accélérateur pour une période de 1 à 1.5 an.
GenePlaza a fait partie de la première édition de Février 2018 :
Startit s’est inspirée du modèle Californien Y Combinator qui est le plus gros accélérateur de startups aux Etats-Unis.
6 centres en Belgique: Leuven, Bruxelles, Anvers, Courtrai, Gand et Hasselt.
3 centres à l’international: Hongrie, New-York et bientôt à San Francisco.
Quel est le concept? Permettre aux startups d’accélérer leur croissance, de rencontrer des pairs, des parrains, des mentors et experts… A la différence de Y Combinator, et c’est peut-être lié à la météo belge 😉 KBC met à disposition des bureaux équipés aux startups.
La Kredietbank, ou KBC, une des plus grandes banques belge, a aussi toute une équipe de plus de 10 personnes totalement dédiées à ce beau projet. Merci la KBC.
Après 4 mois de présence au sein de Startit, nous avons eu l’honneur de présenter un update de la situation concernant GenePlaza. Ce board était composés de l’équipe de Startit ainsi que de différents experts externes.
Aujourd’hui nous sommes à six mois de cette belle expérience, quels sont nos enseignements?
Une start up = une éternelle évolution… tel que dans le grand classique “The lean startup” d’Eric Ries… Build, Measure, Learn, Adjust… Pivot or not?…
Startit @KBC = Communauté locale: les autres membres de startups sont toujours ouverts et prêts à partager leurs expériences
Une startup, une entreprise = ECOUTER LE CLIENT
Les “Community managers” de KBC Startit locaux sont dédiés et passionnés par ce qu’ils font
Nous avons posé notre candidature à Y Combinator, une superbe expérience. Le modèle anglosaxon reste un exemple pour de nombreuses start-ups et de nombreux scales ups. L’Europe est enfin de plus en plus active. Inscrivez vous au blog de Y Combinator
Quand pivoter?
“Les Startups partagent leurs expériences au sein de la communauté Start it @KBC “
C’est un des “plus” incontestable de Start it @KBC: la mise en commun de manière informelle d’expertise et la création d’échange entre les différentes startups.
Notre site à Bruxelles
Nous avons la chance d’avoir sur le site de Start it @KBC Brussels deux community manager: Anna et Laura. Elles connaissent tous les ins et outs de la communauté.
En plus de cela, les installations sont tops: Il y a tout ce dont vous pourriez rêver: plus de 800m2 de bureaux, de nombreuses salles de réunion, une machine à café 😉 , un terrain de mini-panel ;), un parking à vélo.
Venez nous visiter quand vous le voulez.
Quelle différence avec les espaces dédiés à la recherche et au coworking?
Nous avons aussi travaillé dans différents espaces de coworking, ceux-ci sont partagés par différentes sociétés.
Notre première impression, est qu’ici, avec les autres startups, même si les métiers sont différents, nous partageons beaucoup de sujets communs: Acquisition des clients, problématiques techniques, clouds, partages de resources…
Wired to Create, Scott Barry Kaufman et Carolyn Gregoire
Value Proposition Design: How to Create Products and Services Customers Want de Alexander Osterwalder, Yves Pigneur, Gregory Bernarda, Alan Smith, Trish Papadakos
Ce texte est une version modifiée d’un article de blog écrit il y a deux ans. Etant donné l’intérêt croissant pour les tests d’ascendance génétique au cours de ces deux dernières années, la question « qu’est-ce que l’ascendance génétique ? » mérite d’être reposée.
Toute personne ayant utilisé les tests génétiques commerciaux comme ceux proposés par 23andMe, AncestryDNA ou Gencove connaît la notion « d’ascendance génétique ». Après vous avoir fait parvenir un kit salivaire, nous vous renvoyons les résultats de l’analyse qui vous indiquent le pourcentage de votre ADN qui se rapproche le plus de telle ou telle population de la planète.
A un niveau superficiel, il semble relativement facile d’en arriver à cette estimation : on observe le génome de quelqu’un, on applique des statistiques fantaisie et on en arrive à des chiffres du style « 21,5 % Britannique ou Irlandais » ou « 40 % Grande Bretagne, 6 % Irlande, ou « 79 % Europe du Nord et Centrale » (ce sont les chiffres de mes propres résultats, qui m’ont été remis respectivement par 23andMe, AncestryDNA et Gencove. Un lecteur astucieux se demandera : Mais attendez, ces chiffres ne devraient-ils pas être les mêmes partout ? Gardez-donc ceci à l’esprit pour la suite).
Résultats d’ascendance génétique de trois entreprises différentes (GenePlaza, 23andMe et AncestryDNA) pour un mêmeindividu
Dès que l’on se penche un peu plus sur « l’inférence de l’ascendance génétique », on se retrouve très vite aux royaumes de la sociologie et de la psychologie plutôt que dans les domaines de la statistique et de la génétique.
Pour comprendre pourquoi, il est important de commencer par le début : quel est donc le but de « l’inférence de l’ascendance génétique » ?
« Qu’est-ce que l’ascendance génétique » ?
Il est une question utile pour les personnes qui travaillent sur des algorithmes et souhaitent en savoir plus sur l’ascendance en utilisant des données génétiques: « Comment décririez-vous vos ancêtres ? » Essayez donc de répondre à cette question. Demandez à des amis. Enquiquinez des étrangers sur la toile.
What is DNA Ancestry map
Si les gens à qui vous vous adressez ressemblent un tant soit peu à ceux avec qui j’ai discuté, les réponses se diviseront en deux grandes catégories :
Beaucoup de gens utilisent des classifications géographiques pour décrire leurs ascendants, souvent en fonction des frontières politiques actuelles. Par exemple, « Français » ou « Chinois ».
Beaucoup de gens utilisent des catégories ethniques pour décrire leurs ascendants. Par exemple « Juif » ou « Caucasien » [1].
Imaginons que la définition « correcte » de « l’ascendance génétique » ait quelque chose à voir avec ces réponses, données sans trop réfléchir. Cela suggère que les gens s’attendent à ce qu’un « test d’ascendance » génétique augure les catégories géographiques et/ou ethniques dans lesquelles s’inscriraient leurs ancêtres.
Malheureusement, lorsqu’on s’assied et que l’on essaie d’écrire un algorithme pour atteindre cet objectif, on voit immédiatement apparaître deux problèmes décourageants.
Problème numéro 1 : de quelle distance dans le temps parlons-nous ?
Nos ancêtres ont évidemment vécu à des époques différentes. Il se peut que huit de vos ancêtres aient vécu il y a 100 ans, mais que des milliers d’entre eux aient vécu il y a 500 ans. Alors à qui appartiennent les catégories géographique et/ou ethnique que l’on essaie de découvrir ? A des ancêtres ayant vécu 100 ans en arrière ou à ceux qui vivaient il y a 500 ans ? (Ou 1 000 ans ? Ou… ?)
Une première hypothèse raisonnable nous mène à penser que lorsque les gens parlent de leur ascendance, ils se réfèrent en général à des ancêtres récents, de telle sorte que la « bonne » réponse à cette question pourrait être quelque chose de l’ordre de « 100 ans auparavant ». Ce qui n’est pas totalement satisfaisant : aux Etats-Unis il y a beaucoup de gens dont les ancêtres ont immigré des centaines d’années auparavant mais qui pensent que leur ascendance est (par exemple) « britannique » ou « chinoise » plutôt que « michiganienne » ou « californienne ».
Il n’est donc pas toujours évident de savoir à quelle époque se réfèrent les gens lorsqu’ils pensent à leur ascendance. D’ailleurs, il semble plausible que la distance temporelle « correcte » à donner dans un test d’ascendance dépende… de l’ascendance de l’utilisateur. Ce qui devrait nous amener à comprendre que l’ascendance génétique est un concept plus complexe qu’il n’y paraît au premier abord.
Problème numéro 2 : Les marqueurs d’ascendance génétique sont influencés par des facteurs sociaux et politiques
Tout cela devient encore plus évident lorsque l’on aborde un problème fondamental : certaines des catégories que nous considérons comme faisant partie de l’ « ascendance » sont fortement influencées — parfois même déterminées — par des facteurs sociaux et politiques. De toute évidence, aucun marqueur ne change lorsque quelqu’un se convertit au judaïsme, ou lorsque le territoire où vit une personne est annexé par un pays voisin. Mais ces évènements ont souvent des influences dramatiques sur la façon dont les descendants perçoivent leurs ancêtres, de par la transmission culturelle de la langue et des traditions.
En effet, la construction d’une identité ancestrale partagée a été (et reste) une façon de consolider un pouvoir politique sur diverses cultures (voir par exemple le cas de Franco en Espagne). La génétique ne perçoit pas toutes ces données, sauf après des centaines ou des milliers d’années (si les identités partagées influencent les modèles de mariage et/ou de migration ultérieurs).
Une solution possible
Pour contourner tous ces problèmes, on pourrait rêver d’une liste détaillée de nos ancêtres à différentes époques ; pour chaque ancêtre, on indiquerait sa localisation géographique et toutes ses auto-identifications ethniques. On pourrait alors dire, par exemple, qu’il y a 100 ans, 25 % de nos ancêtres vivaient dans l’Illinois et étaient identifiés comme Juifs, alors que 500 ans en arrière, 5 % de vos ancêtres vivaient dans ce que l’on connaît aujourd’hui comme l’Andalousie et étaient identifiés à des Musulmans [2].
Malheureusement, l’obtention d’une bonne partie de ces informations à partir de données génétiques est actuellement impossible, et nous devons donc faire des compromis et des approximations dramatiques [3]. Plus être plus précis, l’approche adoptée par toutes les entreprises commerciales tente d’évaluer les régions géographiques globales où ont vécu vos ancêtres (et dans un tout petit nombre de cas leurs marqueurs d’appartenance ethnique), à une certaine époque indéterminée du passé, probablement quelques centaines d’années auparavant.
Tout cela vous semble un peu vague ? C’est sûrement parce que ça l’est. Les expressions « régions géographiques globales » et « certaines époques indéterminées du passé » laissent énormément de marge de manœuvre et permettent des interprétations fort diverses [4].
Mais la clé du problème réside dans ce qui suit : si l’on substitue l’objectif actuellement irréalisable de comprendre à la perfection la géographie et l’ethnicité de nos ancêtres par celui, plus réaliste, d’une compréhension globale de certains d’entre eux, on peut avancer un peu. Bien sûr, cela peut sembler un peu décevant, en ce sens que nous avons abandonné l’exactitude et l’objectivité promises par un « test génétique », mais il y a tout de même deux raisons de rester optimistes :
Dans de nombreux cas, la compréhension approximative peut déjà être riche de sens. Des millions de personnes ont acheté ces tests. Certaines ont découvert des aspects de leur histoire familiale cachés (je suis d’ailleurs l’une d’entre elles). D’autres ont découvert des erreurs hospitalières qui les ont conduits à des incompatibilités déroutantes entre leurs ascendances culturelle et ethnique. D’autres enfin ont été confrontées à l’héritage génétique de l’esclavage dans leurs propres génomes. Ce type d’informations peut être extrêmement fort.
Plus il y a de gens qui participent, mieux c’est. Le développement des bases de données génétiques permet l’émergence de nouvelles méthodes statistiques pour étudier l’ascendance génétique. Chez Gencove nous avons réussi à mettre à jour nos algorithmes plusieurs fois au cours des derniers mois pour fournir des analyses plus détaillées ; et cela pour une simple et bonne raison : comme pour la plupart des algorithmes d’apprentissage automatique, plus les données d’entraînement sont nombreuses, plus on obtient de bonnes performances, puisque l’on identifie les variantes/combinaisons de variantes qui sont le plus à même de prédire la localisation géographique de vos ancêtres.
Si vous souhaitez nous aider dans notre travail sur la prochaine génération d’algorithmes d’inférence d’ascendance génétique, contactez-nous !
Références:
[1] Bien que le Caucase soit une région géographique, le mot « caucasien » est utilisé aux Etats-Unis en tant qu’identificateur ethnique, pratiquement synonyme de « blanc ».
[2] On pourrait avoir envie de savoir si l’on a réellement hérité du matériel génétique d’un ancêtre ou d’un autre, mais évitons pour le moment d’ouvrir cette boîte de Pandore et supposons que les propriétés de vos ancêtres généalogiques sont les mêmes que celles de vos ancêtres génétiques.
[3] Dans la version antérieure de cet article, j’ai écrit que cela était en fait impossible. Je suis aujourd’hui convaincu que je me trompais, et que c’est un problème extrêmement difficile — mais pas impossible — à résoudre.
[4] Notez les différentes proportions d’ascendance que 23andMe, AncestryDNA, et Gencove m’ont fait parvenir. La plupart des gens considère ces différences comme des solutions algorithmiques à une seule et même question, mais il est tout à fait possible que les algorithmes utilisés par les trois entreprises répondent à des questions légèrement différentes ! Par exemple, il se peut que l’algorithme de 23andMe se penche sur une ascendance à peine plus récente en moyenne que celui d’AncestryDNA (Je crois d’ailleurs que c’est effectivement le cas). Sur ce sujet en général, la publication géniale de Debbie Kennett qui compare les résultats des trois firmes vaut vraiment le détour.
Dans une étude fascinante, le généticien montre les effets des migrations et la nature métisse de l’Humanité grâce aux progrès du séquençage de l’ADN.
« Selon une étude d’ADN ancien, l’arrivée des peuplades du campaniforme a transformé la Grande Bretagne pour toujours » — voilà ce que titre le Guardian au mois de février, à propos de gens dont les ancêtres se trouvaient en Europe Centrale et plus à l’est dans les steppes. L’auteur de cette étude, le généticien de Harvard David Reich, nous livre enfin dans son ouvrage la première ébauche d’une histoire vraie des 5 000 dernières années.
La génétique a commencé à complémenter le travail effectué par les archéologues et les linguistes dans les années 1990, grâce à l’œuvre du mentor de Reich, le généticien italien Luca Cavalli-Sforza ; la génétique était alors le parent pauvre de ces disciplines car elle ne possédait que très peu de données. Mais cela a bien changé. Le génome est un palimpseste qui conserve de fortes traces du passé, de sorte que les populations actuelles peuvent révéler des choses ayant à voir avec les mouvements de celles qui les ont précédées. Ce qui a tout changé, c’est la possibilité, dès 2010, de séquencer l’ADN directement à partir des restes d’êtres humains anciens, parfois vieux de 40 000 ans.
Reich revisite les récentes avancées de la cartographie de l’histoire des premiers Humains, mais ses découvertes les plus spectaculaires concernent un passé plus récent. Les développements les plus importants de l’histoire humaine ont eu lieu au cours des 10 000 dernières années — après le retrait glaciaire — et pour l’Europe, les 5 000 dernières années sont essentielles. Bien que les études d’ADN ancien aient maintenant largement dépassé l’archéologie et la linguistique pour devenir la meilleure source de connaissance des populations humaines préhistoriques et de leurs migrations, elle s’articule avec ces deux disciplines au sein d’un processus où elles se renforcent les unes les autres.
Le travail de Reich peut enfin répondre à la question passionnante qu’avait d’abord posée un fonctionnaire britannique, Sir William Jones, qui a découvert en 1786 le lien de parenté entre le sanscrit et le grec ancien. Ce qui a conduit à la reconnaissance d’une vaste famille de langues indo-européennes qui comprend les langues germaniques, celtiques, italiques, certaines langues du Proche-Orient (l’iranien) et du nord de l’Inde (Hindi, Ourdou, Bengali, Punjabi, Marathi, etc.). Cependant, il n’existait pas à l’époque de consensus sur la façon dont tout cela avait pu se produire. Reich a démontré que les langues indo-européennes et la majeure partie de la composition génétique de l’Europe et du nord de l’Inde résultent de migrations datant d’il y a 5 000 ans, des migrations provenant des vastes steppes, ces plaines herbeuses qui bordent les mers Noire et Caspienne.
Sépulture campaniforme – Image du Musée de la Préhistoire des Gorges du Verdon
La plupart des personnes d’origine européenne entretiennent des liens génétiques et linguistiques étroits avec les peuples du Proche-Orient et ceux du nord de l’Inde. Ces gens étaient des pasteurs nomades qui conduisaient des véhicules à roues, montaient des chevaux domestiqués et commençaient à utiliser des produits laitiers — un ensemble de caractéristiques qui devait garantir leur domination partout où ils allaient. Leurs migrations ont été le moteur de l’âge de Bronze. Homère décrit une société où les chefs de guerre gagnaient en prestige et en richesses en perpétrant viols et pillages. Ce n’est pas très agréable à entendre, mais c’est très conforme à ce que nous savons aujourd’hui des porteurs de la culture de Yamna (les peuples du campaniforme représentaient la vague occidentale des migrations Yamna). A propos de leurs migrations à prédominance masculine, Reich commente : « les hommes des populations les plus puissantes ont tendance à se lier avec les femmes de populations moins puissantes ».
Il reconnaît, et c’est tout à son honneur, les abus commis à partir des histoires d’origines — notamment par l’idéologie nazie — et reconnaît que certains idéologues voudront exploiter — et contester — ses découvertes. Il est fascinant de savoir que la plupart des personnes d’ascendance européenne possèdent des liens étroits, génétiquement et linguistiquement, avec les peuples du Proche-Orient et du nord de l’Inde, mais qu’en est-il globalement et quelles sont les implications de ces nouvelles découvertes ?
La leçon essentielle à tirer de l’ADN ancien est que les populations d’un même endroit ont radicalement changé à plusieurs reprises depuis la grande expansion humaine post-glaciaire, et le fait de reconnaître la nature essentiellement hybride de l’Humanité devrait l’emporter sur toute notion de connexion mystique, de longue date, entre les peuples et l’endroit où ils se trouvent. Nous sommes tous, pour reprendre l’étiquette railleuse de Theresa May, « des citoyens de nulle part ». Les gens du campaniforme ont remplacé 90 % de la population de la Grande-Bretagne il y a environ 4 500 ans.Il faut ajouter à cela l’idée que toute vie, depuis ses débuts, a été un processus essentiellement improvisé et impur.Comme l’indique Reich : « les idéologies qui cherchent un retour à une pureté mystique volent en éclat face aux sciences dures ». Ses découvertes ont aussi d’importantes implications pour le domaine médical. Par exemple, ses recherches en Inde ont montré les conséquences profondes de la consanguinité des systèmes de castes. Il existe par exemple un très grand nombre de maladies récessives — dans certains couples les deux partenaires portent des gènes mutants inscrits depuis longtemps dans la lignée. Ces populations facilitent la chasse aux gènes parce que les gènes récessifs s’accompagnent de marqueurs caractéristiques.
L’image globale peinte par de Reich acquerra avec le temps beaucoup plus de détails — tout comme la grande étude de Darwin, qui n’était que le début de quelque chose, et non pas une fin. Nous devrions lui être reconnaissants, ainsi qu’à sa grande équipe de collaborateurs et à son épouse Eugenie Reich (écrivain scientifique qui a joué un grand rôle dans la création de son ouvrage) puisqu’ils nous transmettent aujourd’hui l’histoire essentielle. Leurs travaux sont captivants, tant par leur clarté que par leur portée.
L’article original a été publié dans The Guardian par Edward Bullmore, responsable du département de Psychiatrie de l’Université de Cambridge, et auteur de The Inflamed Mind (éditions Short Books). La dépression sévit dans de nombreuses familles, c’est bien connu. Mais ce n’est que très récemment, et après énormément de controverses et de frustrations, que l’on commence à savoir comment, et pourquoi. Les découvertes scientifiques majeures signalées la semaine dernière par le Psychiatric Genomics Consortium dans Nature Genetics représentent une avancée durement gagnée pour notre compréhension de ce trouble très commun et potentiellement invalidant.
Photo by Jose A.Thompson on Unsplash
Si vos parents ont souffert de dépression, vos chances d’en pâtir ou d’en avoir pâti augmentent considérablement. Le risque de faire une dépression est de un sur quatre pour l’ensemble de la population — chacun d’entre nous a donc 25 % de chances de vivre une dépression à un moment donné de sa vie. Et si vos parents étaient dépressifs, vos risques de l’être augmentent à un sur trois.
Cependant, la controverse a longtemps tourné autour du débat nature versus éducation. Le fils dépressif d’une mère dépressive est-il victime de l’éducation inadéquate et de l’environnement émotionnellement froid, et peu affectueux que cette dernière lui a procuré au cours de ses plus tendres années ? Ou bien est-il déprimé parce qu’il a hérité des gènes dépressifs de sa mère qui ont déterminé biologiquement son sort émotionnel, indépendamment des compétences parentales ? Est-ce la nature ou l’éducation, la génétique ou l’environnement qui expliquent la dépression au sein des familles ?
Au XXème siècle, les psychiatres sont ingénieusement arrivés à certaines des réponses à ces questions. On avait par exemple constaté que des vrais jumeaux — dont l’ADN est identique à 100 % — étaient plus susceptibles de vivre des expériences de dépression similaires que des faux jumeaux, qui ne partageaient que 50 % de leurs séquences ADN. Ce qui indiquait clairement que la dépression est génétiquement héritable. Mais au vingt-et-unième siècle, l’identité précise des « gènes de la dépression » n’est toujours pas claire. Depuis 2000, des efforts considérables de recherche ont été réalisés pour découvrir ces gènes, mais le champ a été brouillé par de fausses espérances et des résultats peu cohérents.
C’est pour cela que l’étude publiée la semaine dernière constitue un évènement marquant : pour la première fois, des scientifiques du monde entier — avec des contributions majeures de centres de recherche en génétique psychiatrique du Royaume Uni, largement financés par le Medical Research Council à l’Université de Cardiff, à celle d’Edimbourg et au King’s College de Londres — ont réussi à combiner des données d’ADN sur un échantillon suffisamment long pour localiser les régions du génome associées à un risque accru de dépression. On sait donc maintenant, et on peut en être presque certains, quelque chose d’important sur la dépression dont on n’avait pas idée l’année dernière à la même époque : sur les 20 000 gènes que comprend le génome humain, au moins 44 contribuent à la transmission du risque de dépression d’une génération à l’autre.
Oui mais voilà. Cela soulève pratiquement autant de problèmes que cela n‘en résout. Attardons-nous un peu pour commencer sur le fait qu’il existe de nombreux gènes à risque ; chacun d’entre eux contribue à une petite quantité de risques. En d’autres termes, il ne s’agit pas d’une preuve irréfutable, d’un gène solitaire qui fonctionnerait comme un interrupteur binaire, causant inévitablement la dépression chez les gens suffisamment infortunés pour en hériter. Soyons plus réalistes : nous héritons tous de certains de ces gènes impliqués dans la dépression et nos chances de déprimer dépendent en partie de la quantité de ces gènes et de leurs effets cumulés. A mesure que la recherche avance et que des échantillons toujours plus grands d’ADN sont disponibles pour des analyses, il est probable que le nombre de gènes associés à la dépression augmente encore.
Tout cela nous apprend donc que nous ne devrions pas poser de limites entre « nous » et « eux », entre les patients atteints de dépression et les gens bien portants : il est beaucoup plus probable que notre héritage génétique, fort complexe, nous situe sur un continuum de risques que nous partageons tous.
Quels sont ces gènes et que nous disent-ils des causes profondes de la dépression ? Il s’avère que nombre d’entre eux sont connus pour jouer un rôle important dans la biologie du système nerveux. Ce qui correspond à l’idée que les perturbations de l’esprit doivent refléter des perturbations sous-jacentes du cerveau.
Photo by Ben White on Unsplash
Et il y a plus surprenant encore : un grand nombre de gènes influant sur le risque de dépression jouent également un rôle dans le fonctionnement du système immunitaire. Il y a de plus en plus de preuves que l’inflammation, la réaction de défense de notre système immunitaire face à des menaces telles que l’infection, peut provoquer une dépression. On prend également de plus en plus conscience du fait que le stress social peut entraîner des inflammations accrues de l’organisme. On sait depuis des décennies que le stress social est un facteur à très haut risque pour la dépression. Et aujourd’hui, il semblerait que l’inflammation puisse être l’un des chaînons manquants : le stress provoque une réaction inflammatoire de l’organisme, qui entraîne des changements dans la façon de fonctionner du cerveau, lesquels provoquent à leur tour les symptômes mentaux de la dépression.
Connaître les gènes qui influent sur le risque de faire une dépression a aussi des implications importantes pour les traitements pratiques. Il n’y a eu aucune avancée de taille dans les traitements depuis les années 1990 environ, bien que la dépression soit la principale cause unique de handicap médical au monde. Nous devons trouver de nouvelles voies thérapeutiques et la nouvelle génétique est un excellent point de départ pour la recherche de traitements qui puissent réduire de façon plus précise les causes ou les mécanismes de la dépression. On pourrait aisément imaginer la conception, dans le futur, de nouveaux antidépresseurs qui pourraient cibler les protéines inflammatoires codées par les gènes influant sur les risques de dépression. Il est passionnant de penser que la nouvelle génétique de la dépression pourrait également déboucher sur des progrès thérapeutiques en psychiatrie.
Enfin, bien que je pense que ces découvertes de la génétique soient essentielles, je ne les vois pas comme devant mener à des divisions idéologiques. Elles ne prouvent pas que dans le cas de la dépression, « tout se passe dans le cerveau », ni que les traitements psychologiques sont inutiles. La génétique jouera biologiquement un rôle prépondérant mais si nous comprenons mieux le champ d’action de ces « gènes de la dépression », nous pouvons peut-être découvrir que nombre d’entre eux contrôlent la réponse du cerveau ou du corps face au stress lié à l’environnement dans lequel nous évoluons. Et dans ce cas, le meilleur traitement pour un patient pourrait être un médicament ciblant un gène ou une intervention ciblant un facteur environnemental comme le stress.
En bref, une compréhension plus approfondie de la génétique de la dépression nous mènera au-delà de la question de laquelle nous sommes partis : est-ce une question de nature ou d’éducation ? S’agit-il des gènes ou de notre environnement ? La réponse aura sûrement à voir avec les deux.
Merci à Stéphanie Benz pour son article très intéressant dans l’express.
Un millier de gènes liés à des différences de QI entre individus auraient été identifiés. Une découverte controversée.
Certains diront qu’il s’agit d’humour belge – et ils auront raison. Spécialisée dans les tests génétiques “récréatifs”, la start-up bruxelloise GenePlaza propose à ses clients de lire dans leur ADN l’origine de leurs ancêtres, leur vitesse d’endormissement, leur capacité à métaboliser le café et même… leur niveau d’intelligence ! En échange d’un peu de salive, “ils sauront comment leur quotient intellectuel se situe par rapport à celui des autres utilisateurs de ce service”, précise le site de la société. Sérieusement ? “Pas du tout, sourit Alain Coletta, son fondateur. Nous indiquons d’ailleurs bien que ces résultats ne disent rien de l’intelligence réelle des individus, et j’espère que personne ne les comprendra ainsi.” Dans ces conditions, pourquoi proposer un tel test ? “Pour le fun”, répond sans ambages le start-upper.
De nombreux gènes impliqués, avec chacun un effet faible
Pendant longtemps, les recherches dans ce domaine n’ont rien donné de concret. Pourtant, des analyses sur des jumeaux avaient montré que les gènes jouent un rôle dans les capacités cognitives, telles que mesurées par les tests de QI.
Le génome de l’homme de Cheddar, qui a vécu il y a 10 000 ans, suggère qu’il avait les yeux bleus, la peau sombre et des cheveux noirs et bouclés.
Article originel par Hannah Devlin, correspondante scientifique du Guardian.
Une reconstruction médico-légale de la tête de l’Homme de Cheddar, réalisée à partir de nouvelles preuves scientifiques et de son squelette fossilisé. Photographie de Channel 4.
Les premiers Britanniques modernes, qui vécurent il y a environ 10 000 ans, avaient la peau « sombre, voire noire », selon une étude révolutionnaire d’ADN réalisée sur le plus vieux squelette entier de Grande-Bretagne que l’on ait retrouvé.
Le fossile, connu sous le nom de Cheddar Man, a été déterré il y a plus d’un siècle dans la grotte de Gough, dans le Somerset. On a beaucoup conjecturé quant aux origines et à l’apparence de l’Homme de Cheddar puisqu’il a vécu peu de temps après que les premiers colons aient traversé les terres pour passer de l’Europe continentale à la Grande Bretagne, à la fin de la dernière période glaciaire. Les personnes blanches d’origine britannique d’aujourd’hui descendent de ces populations.
On avait commencé par supposer que Cheddar Man avait la peau claire et les cheveux blonds, mais son ADN brosse un tout autre tableau, qui suggère fortement que ses yeux étaient bleus, son teint très sombre — voire noir — et ses cheveux noirs et bouclés.
La découverte montre que les gènes responsables d’une peau plus claire se sont répandus au sein des populations européennes bien plus tard que prévu — et que la couleur de la peau n’a pas toujours été un indicateur de l’origine géographique, contrairement à ce que l’on croit souvent aujourd’hui.
Tom Booth, un archéologue du Musée d’Histoire Naturelle qui a travaillé sur le projet, a déclaré la chose suivante : « Cela montre vraiment que ces catégories raciales imaginaires que nous avons sont vraiment des constructions très modernes, ou très récentes, que l’on ne peut absolument pas appliquer au passé ».
Yoan Diekmann, un biologiste computationnel de l’University College de Londres, qui fait également partie de l’équipe travaillant sur le projet est d’accord : le lien que l’on établit souvent entre le caractère britannique et la blancheur n’était « pas une vérité immuable. Cela a toujours évolué et évoluera toujours ».
Les découvertes ont été révélées avant un documentaire de Channel 4, qui a suivi le projet d’ADN ancien du Musée d’Histoire Naturelle de Londres et la création d’une nouvelle reconstruction médico-légale de la tête de Cheddar Man.
Pour effectuer l’analyse d’ADN, les scientifiques du musée ont percé un trou de deux millimètres de diamètre dans le vieux crâne pour en obtenir quelques milligrammes de poudre d’os. Et c’est de là qu’ils ont extrait le génome complet, qui contenait des indices sur l’apparence et le mode de vie de cet ancien parent.
Les résultats indiquent des origines du Moyen-Orient, suggérant que ces ancêtres auraient quitté l’Afrique, se seraient installés au Moyen-Orient puis dirigés vers l’Europe, avant de traverser le Doggerland, l’ancien pont terrestre qui reliait à l’époque la Grande-Bretagne à l’Europe continentale. Aujourd’hui, il est possible qu’environ 10 % de l’ascendance britannique blanche soit liée à cette population ancienne.
Cette analyse a par ailleurs exclu la possibilité d’un lien ancestral avec les individus qui vivaient dans la grotte de Gough il y a 5 000 ans, individus qui sembleraient avoir accompli des rituels cannibales terribles, comme ronger des orteils et des doigts humains — sans doute après les avoir fait bouillir — ou encore boire dans des tasses crâniennes polies.
La Grande Bretagne a été colonisée périodiquement, puis défrichée au cours des périodes glaciaires jusqu’à la dernière de ces périodes, il y a environ 11 700 ans. Depuis lors, elle a toujours été habitée.
Cependant, jusqu’à présent, on ne sait toujours pas si chaque vague de migrants venait de la même population en Europe continentale ; les derniers résultats suggèrent que cela n’était pas le cas.
L’équipe s’est penchée sur des gènes connus pour être liés à la couleur de la peau, des yeux, et à la couleur et à la texture des cheveux. En ce qui concerne le teint, il existe une poignée de variantes génétiques liées à une pigmentation moindre, dont certaines très répandues dans les populations européennes actuelles. Mais Cheddar Man était doté de versions « ancestrales » de tous ces gènes, ce qui suggère fortement qu’il pourrait avoir eu le teint « sombre, voire noir », mais avec des yeux bleus.
Les scientifiques pensent que la peau des populations ayant vécu en Europe s’est éclaircie avec le temps parce que les peaux claires absorbent plus la lumière du soleil, ce qui est nécessaire pour produire suffisamment de vitamine D. Les dernières trouvailles suggèrent que la peau claire serait apparue plus tard, probablement lorsque l’avènement de l’agriculture a signifié que les gens obtenaient moins de vitamine D malgré le fait que leur régime alimentaire contienne des poissons gras.
Le mode de vie de l’homme de Cheddar était sûrement celui d’un chasseur-cueilleur, qui élaborait des lames tranchantes à partir de silex pour dépecer des animaux, et qui utilisait des ramures de cervidés pour sculpter des harpons destinés à la pêche, ainsi que des arcs et des flèches.
L’application de GenePlaza “K14 Ancient Cultures Admixture” va vous donner la réponse!
Nous sommes très fier chez GenePlaza d’avoir la première application génétique mondiale qui reprend les génomes d’ancêtres du néolithique découverts récemment.
Il s’agit de découvertes fabuleuses, regroupées par Mr Khan au sein d’une même application et permettent d’avoir une compréhension unique de nos origines ancestrales jusqu’à 8.000 ans et ce en incorporant ces dernières découvertes.
Le calculateur ADMIXTURE parcoure votre génome et le compare aux cultures très anciennes d’Europe, d’Afrique et d’Asie Centrale et du Sud.
Mr Khan a dit a propos de sa dernière application K14:
“Ces nouveaux génomes récemment découverts ajoutent à notre compréhension de la démographie des populations d’Europe, d’Afrique et d’Asie. Donc nous pensons qu’il s’agit de l’application sur les origines ancestrale actuellement disponible la plus à jour existant à l’heure actuelle.“
La différence principale avec l’application développée par Mr Khan “Ancient Admixture” est le fait que ce calculateur K14 divise les origines ancestrales en de plus anciens groupes néolithiques.
Comment recevoir cette étude avec votre propre génome?
Une revue rapide de l’application “K14 Ancient Cultures Admixture”
Ces génomes de haute qualité ont apporté beaucoup à notre compréhension de la population démographique en Europe, en Asie et en Afrique. L’algorithme utilisé est détaillé sur le site du créateur; Eurasian DNA.
LE “K14 ANCIENT CULTURES” CALCULATEUR
La motivation derrière ce calculateur provient de la publication d’une douzaine de génomes anciens de haute qualité voir “Mathieson et al., 2018”; “The Genomic History Of Southeastern Europe and in Olalde et al., 2017” et “The Beaker Phenomenon And The Genomic Transformation Of Northwest Europe”, et dans Narasimhan et al., 2018,” “The Genomic Formation of South and Central Asia.”
Pour augmenter la qualité des résultats et l’analyse des variants communs entre notre ADN et les différentes populations de références, seulement les génomes ayant les plus hauts taux de bivalence ont été choisis pour valider les fréquences allèles.
Ce calculateur reprend les génomes anciens disponibles dans les différentes études et permet de représenter les différentes cultures anciennes: Néolithique, Chalcolithiques, Âge de Bronze qui s’étendaient de l’Ouest de l’Europe jusqu’au centre de l’Asie et la Sibérie, et qui ont contribué à la création des gênes de base des différentes populations modernes résidant en Europe et en Asie.
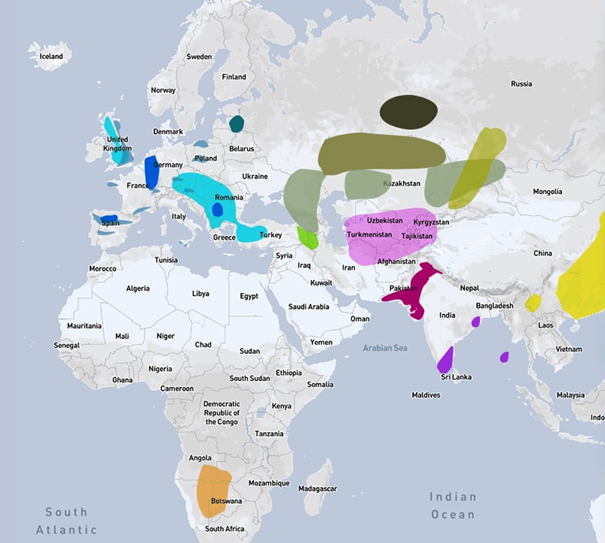
Voici une carte des différentes cultures anciennes existant jusqu’il y a 8.000 ans
La population “Beaker”, dont la traduction littérale est “pot”, est connue pour ses potteries. La culture s’est répandue à travers l’Europe sans doute à partir de la péninsule ibérique jusqu’à la Pologne il y a environ 4700 ans et cette population a existé jusqu’il y à 3800 ans. Cette population semble avoir remplacé la culture “Corded Ware” qui était établie avant leur arrivée dans l’Est de l’Europe.
Avant l’expansion de la culture “Beaker“, la Grande-Bretagne était occupée par les “fermiers Néolithiques” anglais (British Neolithic farmers) qui étaient très proches génétiquement des fermiers Néolithiques Ibériques, suggérant un mouvement vers la Grande-Bretagne depuis l’ouest de l’Europe plutôt que depuis l’Allemagne. Les fermiers Néolithiques du Sud Est de l’Europe et d’Allemagne sont plus que probablement des ancêtres aux fermiers Ibériques et anglais Néolithiques, ceux-ci étant éteint après l’arrivée des Chasseurs occidentaux (Western-European Hunter-Gatherers (WHG) ). Les WHG sont les occupants lors d’une longue période de l’Europe avant l’arrivée des fermiers Néolithiques (Neolithic farmers ) du proche Orient il y a environ 8.000 ans.
Les Western-European Hunter-Gatherers (WHG) ont occupé l’Europe pour quelques millénaires depuis le Paléolithique supérieur et semblent avoir survécus sans mélange génétique jusqu’il y a 7800 ans en Serbie et en Roumanie sous la forme des “Iron Gates HG“. Par la suite, ils ont été absorbés par la culture des fermiers Néolithiques qui s’est répandue depuis l’Anatolie jusqu’en Europe, il y a environ 8.000 ans.
Le deuxième mouvement majeur de population en Europe est venu des Steppes Eurasiennes (Russie) vers l’Est au moment de l’âge de Bronze. Les populations des steppes Eurasiennes (Eurasien Steppe folks) sont elles-mêmes issues de cultures comme Yamna, Srubna et Andronovo et il est fort probable que c’est comme cela que les langues Indo-Européennes ont été introduites en Europe. Les européens actuels sont principalement issus de trois sources principales: WHG, “Neolithic farmers” du proche Orient, et des éleveurs des steppes Eurasiennes “Eurasian steppe pastoralists” , dans des proportions variées. Les gênes des éleveurs des steppes Eurasiennes, “Eurasian steppe pastoralists“, comprennent des gênes des chasseurs Européens, “European Hunter-Gatherers (EHG)”, des chasseurs du Caucase, “Caucasus Hunter-Gatherers (CHG)”, et des fermiers Iraniens du Néolithique “Iranian Neolithic farmer”.
Il y a aussi des contributions mineures au paysage génétique Européen provenant d’Afrique, du Sud-Ouest d’Asie, principalement dans le Sud de l’Europe et d’Asie de l’Est et de Sibérie qui sont plus que probablement arrivée par les populations liées à l’Age de Bronze et à la culture Karasuk à travers les Uralic, Scythians et les différents groupes Turcs.
Voici la liste des cultures anciennes dont nous parlons dans cette application
Ici, nous utilisons aussi pour la première fois, les génomes anciens de “Turan” (actuellement l’Iran, l’Afghanistan, l’uzbekistan, le Turkmenistan et le Tajikistan), les “Indus Valley” (Pakistan actuel), et de nombreuses cultures dans le Kazakhstan et ses environs, qui sont supposées avoir introduit les langues Indo-Européennes dans la région. Les origines de la Steppe Eurasienne lient génétiquement l’Europe et l’Asie du Sud avec l’âge de Bronze. Les populations actuelles du Sud et de l’Ouest de l’Asie doivent leur existence à ces anciennes populations.
Résumé de l’article de Narasimhan et al. 2018 pre-print
Nos données révèlent un ensemble complexe de sources génétiques qui se sont combinées pour former les origines des populations d’Asie du Sud de ce jour. Nous documentons une évolution vers le Sud des origines ancestrales génétiques commencée à partir des Steppes Eurasiennes “Eurasian Steppe” et corrélées avec l’expansion connue des sites d’éleveurs depuis les Steppe de Turan au milieu de l’âge de Bronze (2300-1500 BCE). Ces populations des Steppes se sont mixées génétiquement avec les populations du “Bactria Margiana Archaeological Complex (BMAC)” qu’ils ont rencontré à Turan (à la base les premiers descendants des agriculteurs en Iran) par la suite.
Les populations des Steppes se sont intégrées plus au sud à travers le deuxième Millénaire avant JC, et nous voyons qu’elles se sont mélangées avec une population du Sud que nous documentons à différents sites avec des individus particuliers montrant un mélange distinctif d’origines liées à des agriculteurs Iraniens “Iranian agriculturalists” et à des chasseurs d’Asie du Sud “South Asian hunter-gathers”. Nous appelons ce groupe “Indus Periphery ” car ces populations ont été trouvées en contact avec les cultures “Indus Valley Civilization (IVC)”, à la frontière Nord de cette population, et aussi parce qu’ils sont génétiquement semblables aux groupes “post-IVC” dans la “Swat Valley” du Pakistan.
En co-analysant les anciens codes génétiques et les données génomiques de diverses populations actuelles d’Asie du Sud, nous montrons que les populations liées à “Indus Periphery” sont la source génétique la plus importante en Asie du Sud – hypothèse cohérente avec l’idée que les populations “Indus Periphery” nous fournissent la première possibilité d’analyse des populations ancestrales de IVC – et nous développons actuellement un modèle pour la formation de groupes d’Asie du Sud proches au niveau temporel et au niveau géographique des sources “Indus Periphery“. Nos résultats montrent comment les origines ancestrales des Steppes sont liées génétiquement avec les populations d’Europe et du Sud d’Asie dans l’Age de Bronze, et identifie des populations qui plus que probablement sont responsables pour répandre les langues Indo-Européennes à travers la plupart de la région Eurasienne.
Monsieur Khan est le scientifique qui a développé l’application K14. Voici son site internet: EurasianDNA.com
Quels sont les principes sur lesquels s’appuie l’application?
Cette application est dédiée à augmenter la compréhension des évolutions des différentes populations et cultures à travers les siècles. Pour faciliter cela, l’auteur, Monsieur Khan, emploie un arsenal d’outils, incluant les programmes tels que:
1- l’ “ADMIXTOOLS” du laboratoire Reich Lab: Qui permet d’analyser de manière formelle les génomes et le partages de gênes et de modéliser des exemples à partir de données ancestrales (qpDstat, qpAdm, f3, etc)
2- “PLINK”: Pour préparer et parcourir les données d’ADN
3- “BEAGLE”: Pour le phasage, l’imputation et l’analyse IBD
4- “ADMIXTURE”: Pour le regroupement des individus en classes basé sur des fréquences d’allèles partagées pour certains allèles dérivés.
Références:
1. “The Genomic History of South-eastern Europe, Iain Mathieson et al., 2018.”
2. “The Beaker Phenomenon and the Genomic Transformation of Northwest Europe, Iñigo Olalde et al., 2017.”
3. “The Genomic Formation of South and Central Asia, Narasimhan et al., 2018.”
L’article original écrit par Anna Clausen, 2017 école de journalisme de U.C. Berkeley et student fellow au Pulitzer Center, est publié dans le site du pulitzercenter ici. Cette recherche a été soutenue par le Pulitzer Center.
Une sculpture d’ADN au siège de deCODE Genetics à Reykjavik. L’entreprise génétique affirme qu’elle possède toutes les informations nécessaires pour identifier avec précision presque toutes les personnes porteuses d’une mutation BRCA en Islande.
Une sculpture ADN ā deCODE Genetics, Reykjavik. La compagnie dit avoir les informations suffisantes pour identifier tous les porteurs de mutation BRCA an Islande. Avec la permission de Anna M. Clausen
REYKJAVIK—C’était son premier jour de vacances d’été, en 2015. Erna Ingibergsdóttir se prélassait chez elle, regardant ses deux plus jeunes enfants jouer. Et puis le téléphone a sonné. C’était au sujet de la protubérance dans son sein.
«J’étais tellement sûre que ce n’était rien», dit-elle. «Puis la dame qui m’a appelé a voulu que je passe chercher mes résultats».
Ingibergsdóttir a refusé. La dame devrait donc le lui dire par téléphone. Deux semaines plus tard, elle a subi une double mastectomie.
Avec son regard d’éternelle optimiste Ingibergsdóttir est presque trop positive. Lorsqu’elle a annoncé la mauvaise nouvelle à une amie, elle s’est empressée d’ajouter de bonnes nouvelles —elle allait pouvoir avoir « des seins canons ! ». Elle admet malgré tout que le traitement a été très lourd pour elle. Elle regarde par la fenêtre d’un café du centre-ville de Reykjavik, deux ans après le diagnostic, et son sourire omniprésent depuis maintenant 47 ans semble s’évanouir dans ses yeux.
«J’ai vraiment été très, très malade», dit-elle, le côté droit de ses lèvres tressaille. «La chimio c’était dur ; je ne recommande pas».
Dans la plupart des cas, de telles maladies ne peuvent être évitées. Mais il y avait de fortes chances d’éviter le cancer d’Ingibergsdóttir, sans le paradigme installé de longue date de l’éthique médicale : le droit de ne pas savoir.
Ingibergsdóttir est l’une des 2 400 islandais porteurs d’une mutation du gène BRCA2. Ce qui représente 0,8 % de la petite nation insulaire. La mutation, comme la mutation du gène BRCA1 est devenue célèbre grâce à un op-ed d’Angelina Jolie dans le New York Times. Elle a été associée à un risque fortement accru de cancer du sein et des ovaires pour les femmes, et de cancer de la prostate pour les hommes.
Les femmes porteuses d’une mutation BRCA2 ont en moyenne un risque de cancer du sein de 69 %. Pour certaines, selon les antécédents familiaux, le risque peut dépasser les 80 %. La bonne nouvelle est que le risque peut être réduit d’environ 90 % grâce à des chirurgies préventives, comme la mastectomie radicale qu’a subie Angelina Jolie. Ingibergsdóttir n’a jamais eu le choix.
Erna Ingibergsdóttir diagnostiquée avec un cancer du sein en 2015. Elle était porteuse d’une mutation sur le gène BRCA2. Avec la permission de Anna M. Clausen
Le gouvernement islandais propose un service de conseil en génétique relativement accessible. Mais à l’exception d’un seul parent connu, la famille d’Ingibergsdóttir n’a pas d’antécédents de cancer du sein, alors elle n’est jamais allée faire d’analyses. Comment aurait-elle pu savoir?
Aux Etats-Unis, une femme sur 500 est porteuse de mutations BRCA1 ou BRCA2. Collecter les données pour les retrouver toutes serait une tâche colossale. Mais en Islande, le travail a déjà techniquement été effectué. L’entreprise biopharmaceutique deCODE Genetics affirme avoir recueilli suffisamment de séquences d’ADN complètes pour connaître avec précision la composition de l’ADN de pratiquement tous les Islandais, une nation qui compte à peu près 340 000 individus. Au fil du temps, les Islandais ont préservé des registres généalogiques obsessionnels et la plupart d’entre eux peuvent retracer leur lignée pour remonter jusqu’à des ancêtres communs. Ces registres, associés aux séquences d’ADN des données cryptées de deCode signifient que l’entreprise détient des informations sur tous les porteurs de mutations BRCA possibles, même ceux qui n’ont jamais subi de tests génétiques ni participé aux études de la société.
Depuis 2013, Kári Stefánsson, le PDG de deCode, se bat pour contourner le droit de ne pas savoir, inscrit dans la loi. Il voudrait « appuyer sur un bouton » et découvrir l’identité de chaque porteur de BRCA du pays. Il pense que lorsqu’il s’agit de sauver des vies, la loi devrait être contournée ; toutes les personnes porteuses d’une mutation devraient être informées.
«Si quelqu’un disparaît sur les Hautes Terres nous envoyons des équipes de quelques centaines de chercheurs pour les trouver », dit-il. « On le fait sans leur demander la permission. On enfreint tout autant leur droit d’être laissés tout seuls que lorsque l’on tente de sauver les vies des gens qui portent ces mutations».
Stefánsson affirme qu’il n’est pas contre le droit de ne pas savoir. Il pense simplement que le droit de vivre est plus important.
«Je dirais que c’est un peu fou, un peu vicieux », dit-il. « On ne laisse pas les gens mourir si jeunes si on peut les aider, point final!»
Beaucoup de gens le voient de cette façon — mais, et c’est étonnant, Ingibergsdóttir n’en fait pas nécessairement partie. La plupart des membres de sa famille élargie a subi des tests génétiques pour le BRCA2, mais quelques personnes ne veulent toujours pas savoir, voire peut-être jamais. Parmi ces personnes, sa fille de 23 ans, dont la grand-mère paternelle est également porteuse d’une mutation.
Ingibergsdóttir ne veut pas faire pression sur sa fille. Après tout, elle est encore jeune et ces informations influenceront toutes ses décisions majeures à partir du moment où elle saura.
«Si j’avais su, je ne suis pas sûre que j’aurais eu mes deux derniers enfants », dit-elle. « Je ne veux pas répandre ça. Je me sens coupable en tant que mère».
Vigdís Stefánsdóttir, conseiller en génétique à l’Hôpital universitaire nationale d’Islande, a vu des personnes appartenant à des familles que l’on savait porteuses du BRCA2 venir pour un diagnostic jusqu’à 20 ans après la découverte de la mutation. Dans son tiroir, elle a beaucoup de dossiers contenant des informations sur les gens qui sont venues mais n’ont jamais terminé le processus. Parfois, elle rappelle et rappelle les gens, lorsqu’elle est en possession de leurs résultats de tests sanguins, sans jamais arriver à les contacter.
«Alors je laisse filer et je range le dossier dans le tiroir», dit-elle. «Parce que je sais que le la personne qui a consulté n’est pas prête à connaître les résultats».
Vigdís Stefánsdóttir rencontre des Islandais qui veulent savoir si Ils ont porteurs d’une mutation BRCA2. Avec la permission de Anna M. Clausen
Il y a beaucoup de raisons pour lesquelles quelqu’un fait marche arrière, dit Stefánsdóttir. Savoir ce que prédisent nos gènes peut sauver des vies, mais cela peut également mener à une existence pleine de préoccupations et de problèmes de santé mentale quand les personnes porteuses sont dans l’attente. Elle prétend que seul le patient peut décider si le moment est venu.
«La règle est la suivante : moins on peut en faire pour la maladie, moins les gens veulent savoir s’ils sont en danger. C’est le cas avec Alzheimer : chaque fois que l’on oublie quelque chose, que l’on oublie ses clés quelque part – attendez, les symptômes ont-ils commencé? C’est un peu la même chose avec les gènes BRCA. Si je ressens une douleur dans la poitrine, est-ce que c’est le premier signe d’un cancer du sein?»
Elle dit que l’information transforme les gens —une fois que l’on sait, il n’y a pas de retour en arrière.
«Je n’aime pas parler du droit de ne pas savoir. Le droit de savoir c’est quand c’est bien pour vous».
Cela sonne particulièrement vrai pour Íris Katrín Barkardóttir, qui a 31 ans et a attendu presque dix ans pour faire un diagnostic. Sa mère, décédée d’un cancer au mois de mars 2011, avait raconté qu’elle était porteuse de la mutation quand Barkardóttir avait 20 ans. Elles avaient toutes les deux décidé qu’elles ne voulaient pas savoir.
«Etre vivant c’est mortel, et si on pense toujours aux « et si », on se retrouve coincé dans un cycle d’angoisses», dit-elle. «Je souffre d’anxiété alors j’essaie de faire taire ces pensées, mais elles réapparaissent évidemment».
Assise dans sa cuisine lumineuse dans le quartier de Laugardalur à Reykjavik, Barkardóttir caresse avec amour un petit chiot blanc installé sur ses genoux, se réconfortant autant qu’elle réconforte le chien pendant qu’elle raconte son histoire.
Elle a vu sa mère passer par une chimiothérapie atroce et par de multiples traitements de radiothérapie, et perdre à un moment donné la peau de ses mains et de ses pieds. L’expérience l’a marquée mentalement et l’idée d’avoir à traverser tout ça était trop dure à vivre. Le droit de ne pas savoir l’a emporté sur celui de savoir.
Cependant, Barkardóttir en est venue à changer d’avis. Elle a fini par faire un test à 29 ans, et il lui a fallu un certain temps pour programmer son premier examen des seins. Lorsque l’image de l’IRM a montré une tâche sur son sein, elle a fondu en larmes.
«J’ai pleuré pendant 24 heures d’affilée », dit-elle. «Je me sentais comme une bombe à retardement».
Elle était convaincue qu’elle allait mourir et rongée par les remords. Pourquoi n’y était-elle pas allée plus tôt ? Elle devait passer d’autres examens la semaine suivante mais a supplié l’équipe médicale du service de dépistage de reporter son rendez-vous au lendemain.
En fin de compte, la tâche s’est avérée être une fausse alerte.
Barkardóttir a l’intention de se faire faire une mastectomie préventive et envisage également une ovariectomie (ablation chirurgicale des ovaires), plus tard dans sa vie. Pendant cette période où elle pensait qu’il était trop tard, elle aurait aimé que quelqu’un lui impose des informations, mais aujourd’hui elle est contente de pouvoir contrôler le timing.
«J’ai traversé des moments difficiles après le décès de maman et je ne pouvais pas alors avoir ce nuage infernal planant au-dessus de ma tête. C’est quelque chose qui demande une certaine maturité mentale. Il était pour moi crucial de ne pas savoir plus tôt».
Bien sûr, pour Barkardóttir, c’est facile à dire, maintenant. En ne sachant pas, elle s’est évité dix ans d’examens du sein crispants et d’être transie de peur. Mais qu’est-ce que vivre avec la peur ou subir des opérations potentiellement inutiles, par rapport à ne pas vivre du tout? Qu’en est-il de ceux qui ne savent pas jusqu’à ce qu’il ne soit trop tard? Un comité gouvernemental travaille à un terrain d’entente.
«Le groupe est d’accord sur le fait que les droits de ceux qui ne veulent pas savoir — une posture qu’il est très important de respecter — ne doivent pas faire obstacle à ceux qui veulent savoir et qui en ont besoin », dit le président du comité, Sigurður Guðmundsson, Directeur Médical; il ajoute qu’il est de la plus haute importance que ce problème soit résolu.
«Nous avons longuement discuté du consentement présumé, mais on nous a fait remarquer que tous les chemins visibles allaient vraiment à l’encontre des lois sur la protection de la vie privée — et de la constitution.»
Le comité a donc cherché d’autres moyens de combler le vide. En fait, aux dires de Guðmundsson, une solution impliquant un portail national de la santé semblerait être en vue.
Íris Katrín Barkardóttir a attendu près de 10 ans avant de décider de savoir si elle était porteuse d’une mutation BRCA2. Avec la permission de Anna M. Clausen
Les informations génétiques provenant d’études scientifiques, comme les informations sur les personnes porteuses de mutations BRCA, pourraient être non-cryptées et téléchargées sur le site du portail, où les utilisateurs pourraient avoir accès à leur dossiers médicaux. De nos jours, l’une des principales préoccupations concerne les personnes qui ne savent pas qu’elles devraient se faire examiner, mais le portail mettrait cette suggestion au tout premier plan. Au lieu d’avoir à chercher des réponses dans un établissement médical, les utilisateurs pourraient accéder en un clic à l’état de leurs gènes BRCA ainsi qu’à des instructions sur la façon de procéder.
L’idée n’est pas parfaite. Tout d’abord, il est préférable de recevoir une mauvaise nouvelle en personne de la part d’un professionnel de la santé plutôt que de la lire sur le net, peu importe le matériel d’aide fourni. Cette démarche résout en revanche la question de l’intrusion et donne du pouvoir à l’individu.
Il faut aussi que les chercheurs puissent fournir ce genre d’information aux personnes qui le souhaitent, dit Guðmundsson. Indépendamment de la façon dont est reçue l’information, il dit que chacune de ces personnes devrait toujours être orientée vers un conseiller pour un diagnostic plus approfondi. « Il existe d’autres approches, mais probablement aucune qui ne soit meilleure que celle-ci ».
Stefánsdóttir est d’accord. Si la société décidait qu’elle veut en fait que les chercheurs informent les gens des risques pour la santé chaque fois qu’ils en rencontrent, il faudrait mettre en place tout un système, non seulement pour le droit de ne pas savoir, mais aussi pour des questions de logistique.
«Un système qui permet à chacun de décider où, quand, et dans quelles circonstances nous accédons à l’information», dit-elle. Elle ajoute que la découverte constante est inhérente à la recherche.
«On ne peut pas espérer des chercheurs qu’ils contactent chaque participant chaque fois que cela se produit».
L’article original écrit par Anna Clausen, 2017 école de journalisme de U.C. Berkeley et student fellow au Pulitzer Center, est publié dans le site du pulitzercenter ici. Cette recherche a été soutenue par le Pulitzer Center.
Retrouvez l’article publié le 24 Févier dans l’Echo en suivant le lien.
“En 2007, Steve Jobs avait déboursé pas moins de 700.000 dollars pour faire analyser la séquence ADN de son cancer du pancréas. Aujourd’hui, si l’on veut en savoir plus sur notre prédisposition à certaines maladies ou l’origine de nos ancêtres, cela ne coûte que quelques centaines d’euros.”
Un petit peu de salive et beaucoup de patience
Concrètement, comment ça marche? Soit vous disposez déjà des données de votre ADN via une autre société comme 23andMe, Ancestry ou Gencove.Vous les téléchargez sur la plateforme de GenePlaza et vous avez accès à une série d’applications génétiques dont les prix varient entre 0,99 euro et 14,99 euros. Soit vous commandez un kit de prélèvement de salive (145 euros), vous le recevez dans les 3 à 10 jours par la poste et vous faites le test chez vous. Attention à bien lire le mode d’emploi: il est, par exemple, proscrit de boire, manger, chiquer ou fumer trente minutes avant le prélèvement.
Quelles applications?
Parmi ces applications génétiques, on en trouve sur les origines ethniques, la métabolisation du café, la perception des odeurs ou encore la prédisposition au neuroticisme.
Récemment, Gene Plaza a mis à la disposition de ses utilisateurs une nouvelle application, baptisée 500k, basée sur les résultats d’une étude de UK Biobank. Elle permet de dégager strong> certaines prédispositions sur la base de questions sur l’historique médical/santé de 500.000 personnes. “Ces 500.000 personnes ont répondu à une série de questions médicales, sociales, familiales. On y répond soit via un touchscreen, soit via une interview avec un expert. S’il y a des variants enrichis sur une question particulière, cela permet de faire avancer la compréhension. On essaie de comprendre, par exemple, pourquoi les personnes qui ont ces variants ont une voiture rouge”, explique Alain Coletta.
Retrouvez tout l’article ici:
Lancement de GenePlaza en Europe, la première plateforme génétique en ligne
Actif depuis 2012 dans l’analyse des données génétiques, Alain Coletta et Robin Duqué lancent GenePlaza:
“La plateforme offre la possibilité aux particuliers d’accéder, à prix démocratique, aux informations relatives à leurs génomes et de découvrir l’incidence de l’ADN sur leurs modes de vie.”
Voulez- vous par exemple savoir si vous êtes plus performant le matin ou le soir?
Voulez-vous connaître la façon dont votre organisme réagit à certains aliments, votre tolérance au lactose ?
Voulez-vous apprendre comment votre palais apprécie le goût de certains aliments ?
Voulez-vous connaître vos origines?
Les réponses à ces questions se trouvent dans notre ADN. Grâce à la plateforme Gene Plaza, toute personne peut dorénavant obtenir et stocker ses données génétiques et les interpréter de manière à prendre des mesures pour améliorer son mode de vie.
Cette interprétation se fait grâce à des applications développées par des scientifiques du monde entier et accessibles via un smartphone ou un ordinateur.
GenePlaza est la première plateforme gérée par une société européenne offrant ce service en ligne à des particuliers .
A partir du mois d’Avril 2019, il sera étendu géographiquement vers les pays européens voisins (France, Royaume-Uni, Pays-Bas et Luxembourg) et visera à proposer une gamme plus étendue de plus de 100 applications génétiques.
Il existe aujourd’hui 8 millions d’individus disposant déjà de leurs données génétiques. On prévoit que cette population atteindra les 20 millions d’ici 2022. La plateforme GenePlaza vise à couvrir 15% de ce marché, soit 3 millions d’usagers qui auraient alors directement accès à leurs propres informations génétiques actualisées.
En pratique:
L’analyse de l’ADN se fait via la salive. Le particulier commande un kit de test ADN qui lui est envoyé à domicile. Il dépose dans un tube-test un échantillon de salive qu’il renvoie directement au laboratoire de GenePlaza pour analyse. Une fois l’analyse terminée, la personne peut accéder à ses données génétiques sur la plateforme informatique de GenePlaza. Elle peut ensuite explorer son ADN grâce aux multiples applications disponibles en ligne qui lui permettent de mieux comprendre des aspects relatifs à sa santé, à sa nutrition, ses performances sportives, etc…
A propos de GenePlaza:
En 2012, Alain Coletta, Francais d’origine et docteur en bioinformatique, lance une Spin-off d’universités Bruxelloise dans le but de développer InSilicoDB, une plateforme pour la gestion et l’analyse de données génétiques destinées aux chercheurs biologistes.
Avec GenePlaza, l’activité est étendue aux particuliers et offre ainsi aujourd’hui une nouvelle plateforme d’applications développées par des scientifiques pour le grand public et compte déjà plus de 10.000 utilisateurs.
Alain Coletta, docteur en bioinformatique et CEO dit : «GenePlaza est une percée dans le monde de la génétique. C’est la première fois que les particuliers peuvent avoir accès à leur ADN et acheter en ligne des applications spécifiques en fonction de leur intérêt. Ils peuvent également autoriser le partage de leur information génétique avec des chercheurs biologistes en vue d’améliorer la recherche scientifique et obtenir en échange les informations les plus pointues sur leurs gènes et leurs conséquences. »
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok